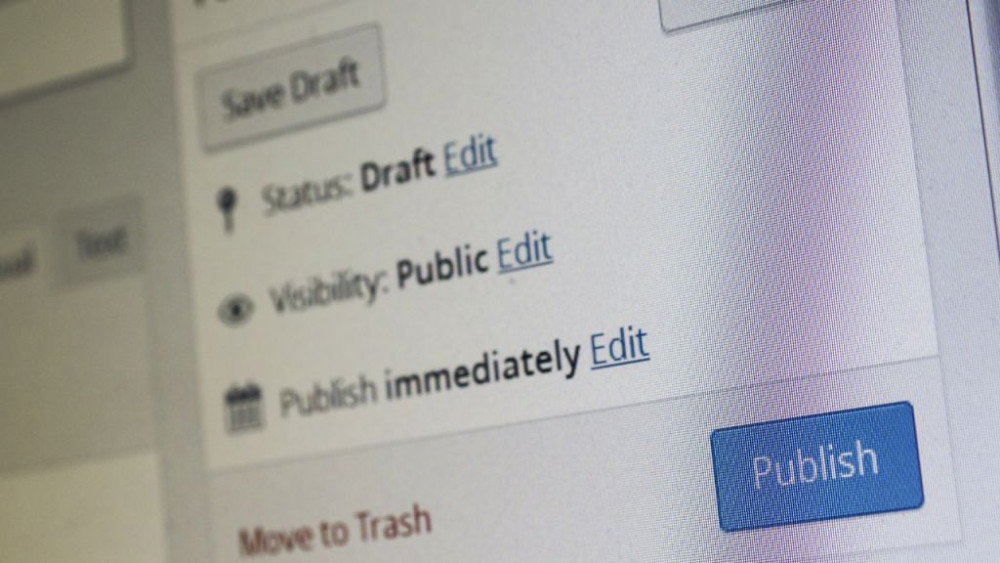
Crawling Indexing and Ranking When developers and SEOs ask the question if Googlebot can crawl JavaScript we tend to think the answer is 'yes Because Google does actually render JavaScript and extracts links from it and ranks those pages.
The crawler and indexer work close together the crawler sends what it finds to the indexer and the indexer feeds new URLs discovered by for example executing JavaScript to the crawler.
It then has to wait for the indexer to render these pages and extract new URLs which the crawler then looks at and sends to the indexer.
And because pages are crawled and rendered according to their perceived importance you could actually see Google spending a lot of time crawling and rendering the wrong pages and spending very little time on the pages you actually want to rank.
Despite the incredible sophistication of Googlebot and Caffeine what JavaScript content actually does is make the entire process of crawling and indexing enormously inefficient.
Read more
Related items: